How to Think Like Git
This first thing that is important to understand about Git is that it thinks about version control very differently than Subversion or Perforce or whatever SCM you may be used to. It is often easier to learn Git by trying to forget your assumptions about how version control works and try to think about it in the Git way.
Let's start from scratch. Assume you are designing a new source code management system. How did you do basic version control before you used a tool for it? Chances are that you simply copied your project directory to save what it looked like at that point.
$ cp -R project project.bak
That way, you can easily revert files that get messed up later, or see what you have changed by comparing what the project looks like now to what it looked like when you copied it.
If you are really paranoid, you may do this often, maybe putting the date in the name of the backup:
$ cp -R project project.2010-06-01.bak
In that case, you may have a bunch of snapshots of your project that you can compare and inspect from. You can even use this model to fairly effectively share changes with someone. If you zip up your project at a known state and put it on your website, other developers can download that, change it and send you a patch pretty easily.
$ wget http://sample.com/project.2010-06-01.zip $ unzip project.2010-06-01.zip $ cp -R project.2010-06-01 project-my-copy $ cd project-my-copy $ (change something) $ diff project-my-copy project.2010-06-01 > change.patch $ (email change.patch)
Now the original developer can apply that patch to their copy of the project and they have your changes. This is how many open source projects have been collaborated on for several years.
This actually works fairly well, so let's say we want to write a tool to make this basic process faster and easier. Instead of writing a tool that versions each file individually, like Subversion, we would probably write one that makes it easier to store snapshots of our project without having to copy the whole directory each time.
This is essentially what Git is. You tell Git you want to save a snapshot
of your project with the git commit command and it basically
records a manifest of what all of the files in your project look like at
that point. Then most of the commands work with those manifests to see
how they differ or pull content out of them, etc.
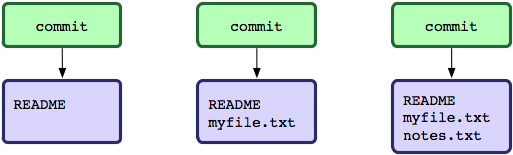
If you think about Git as a tool for storing and comparing and merging snapshots of your project, it may be easier to understand what is going on and how to do things properly.